
差距一目了然!云知声U2测评实现智能体执行能力跨越式突破
2026-06-30 16:09:58 来源:科智网
提及国产大模型,很多人印象还停留在“能用”,但离“好用”还有一段距离。随着海外权威评测平台LLMStats最新榜单更新,云知声自研U2原生智能体大模型交出亮眼成绩单,位列全球模型厂商第八,印证国产大模型在综合能力、自主任务执行两大维度实现关键跨越,打破行业固有认知。
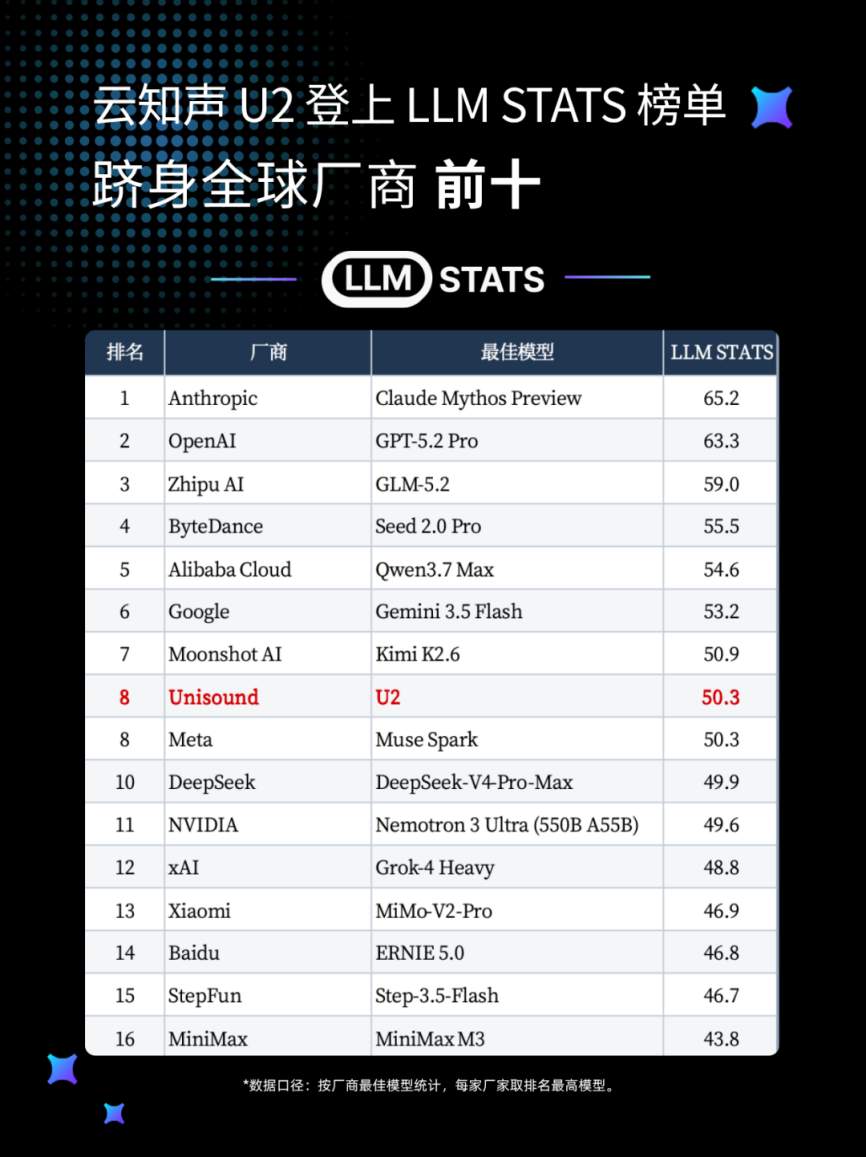
行业当前多数智能体产品仍停留在“对话模型外挂工具”的浅层阶段,仅能输出规划框架,无法完成完整业务交付,复杂长链路任务极易出现流程断裂、素材零散等问题。为验证U2实战能力,测试方下达完整落地需求:自主产出包含六页内容的人工智能行业年度研究PPT,配套matplotlib生成标准化行业图表,数据贴合产业客观规律,统一科技视觉风格。该任务串联需求拆解、数据模拟、代码绘图、文档整合、风格统一多道工序,对模型连续执行、自我纠错、成果闭环能力提出严苛考验。
生成这样一份《人工智能大模型行业研究年度报告》PPT,包含封面、目录、市场规模与算力需求、开源vs闭源生态对比、落地行业渗透率、产业链价值分布共6页。所有图表用matplotlib生成后嵌入,数据可以模拟,但必须符合行业常识,整体风格要有科技感。
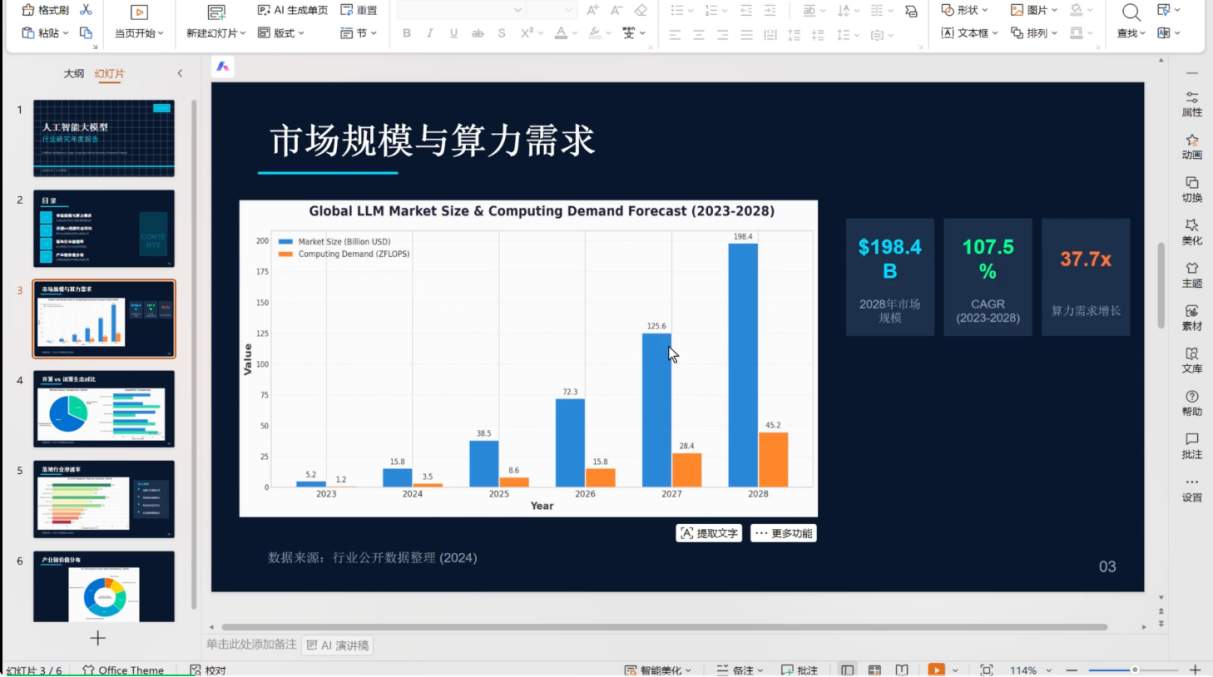
这个任务的难点不在“写PPT大纲”,而在链路长。它要先理解报告结构,再设计每页内容;要生成数据,再判断数据是否合理;要画图,再把图表嵌入幻灯片;最后还要保证整份PPT风格统一、逻辑闭合。任何一步偷懒,结果都会变成一堆散装素材。
U2这次给出的不是一段建议,而是完整推进了任务链。它先拆页,再定义每页核心信息,随后用代码生成图表,把市场规模、算力需求、生态对比、行业渗透率、价值分布这些内容可视化,最后把图表和文字组织成一份可交付PPT。
这也是U2和普通聊天模型的分水岭。普通模型擅长回答,U2更强调执行。它的Agent-Harness协同训练,把任务规划、工具调用、过程纠错和结果验收都纳入训练路径。
放到开发者场景里,U2的价值会更明显。它不只是能给你一个方案,还能把方案推进到代码、文件、图表、报告这些可交付物上;不只是能回答“怎么做”,而是能一步步把“做出来”这件事往前推。官方也强调,U2支持OpenClaw、Hermes等主流Agent开发框架,并已上线云知声TokenHub,面向个人、开发者和组织开放。
【广告】免责声明:本内容为广告,相关素材由广告主提供,本文仅代表作者个人观点,与本网无关。本网发布目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,广告内容仅供读者参考,请自行核实相关内容。
